开云盘口
开云的世界杯中国登录网址 机器东谈主自总结的翻新, 让星海图横扫了7大具身评测基准


编著|Panda
上个月,Physical Intelligence 发布了新一代基础模子 π0.7,激勉了一轮对具身智能泛化才能的询查高涨。而就在今天,北京的星海图(Galaxea)又为寰宇带来了 G0.5。

视频聚合:https://mp.weixin.qq.com/s/nTJCsLfKtMglgicr_oqKbA
在横跨仿真、真机、零样本、长程任务的 7 个独处基准上,G0.5 全面超越 π0.5,并在其中多项上赢得 SOTA。
这不是靠堆数据堆出来的收成。G0.5 的底层逻辑是对现时 VLA 模子主流架构作念出了一个根人道的判断,并用实验数据讲明了这个判断是对的。
7 大基准,全面领跑
G0.5 的收成遮掩了 VLA 领域最主流的评测维度,数据如下:
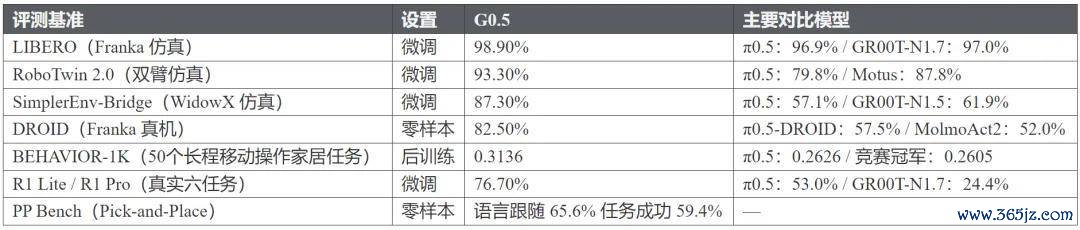
这 7 项评测范围平凡,从不同角度检测了一个通用 VLA 模子信得过需要具备的才能:开箱即用的零样本迁徙、跨实质微调效用、仿真环境下的指示奴婢以及履行寰宇中的长程复杂操作。
要在这些维度上同期保持起首,单点性能优化是作念不到的。
零样本迁徙才能(DROID)
DROID 是面前鸿沟最大的真是机器东谈主操作数据集之一,包含来自多个实验室、多种场景的 Franka 机械臂演示数据。
G0.5 在弥散莫得针对该平台进行任何微调的情况下,径直部署于 10 项桌面操作任务,平均胜利率达到了 82.5%,特等 π0.5-DROID(57.5%)整整 25 个百分点。
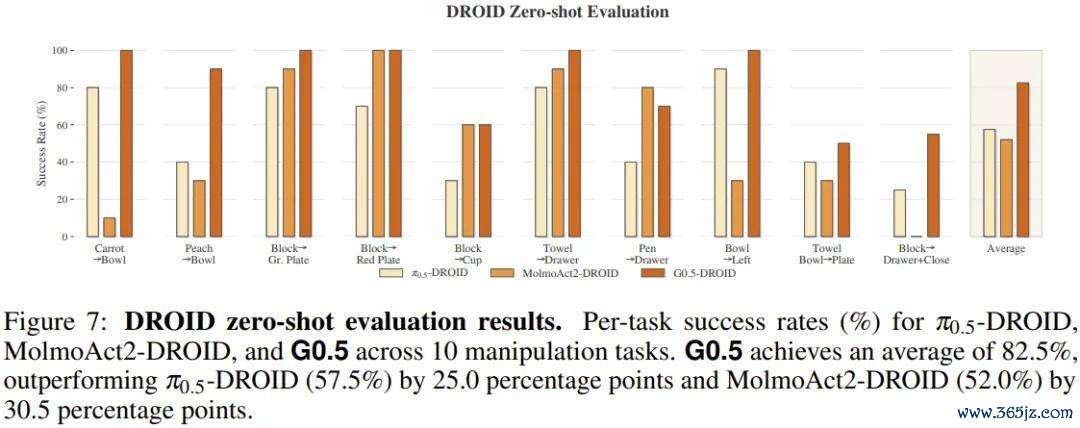
尤其在需要多要领划定扩充的任务「将积木放入抽屉并关闭抽屉」上,MolmoAct2 弥消失败,而 G0.5 特等半数闇练胜利完成。零样本才能径直反应的是预训导阶段千里淀下来的可迁徙操作先验,而不是针对某一平台的过拟合。
真是机器东谈主微调(R1 Lite / R1 Pro)
在星海图自研平台上,G0.5 和 π0.5、GR00T-N1.7 使用接头的训导数据、接头的计较预算(各 16 张 H20 GPU),永别完成折叠毛巾、折叠纸箱、铅笔盒整理和箱子搬运堆叠等 6 项任务的评测。这些任务王人不是「抓取摈弃」级别的简略操作,比如折叠毛巾要求机器东谈主从篮子里取出一条变形毛巾,通过双臂配合将其张开、铺平、按预定步地折好,再放入指定区域,任何一步的抓执力度或拉伸张力出现偏差,王人会导致通盘进程为山止篑。
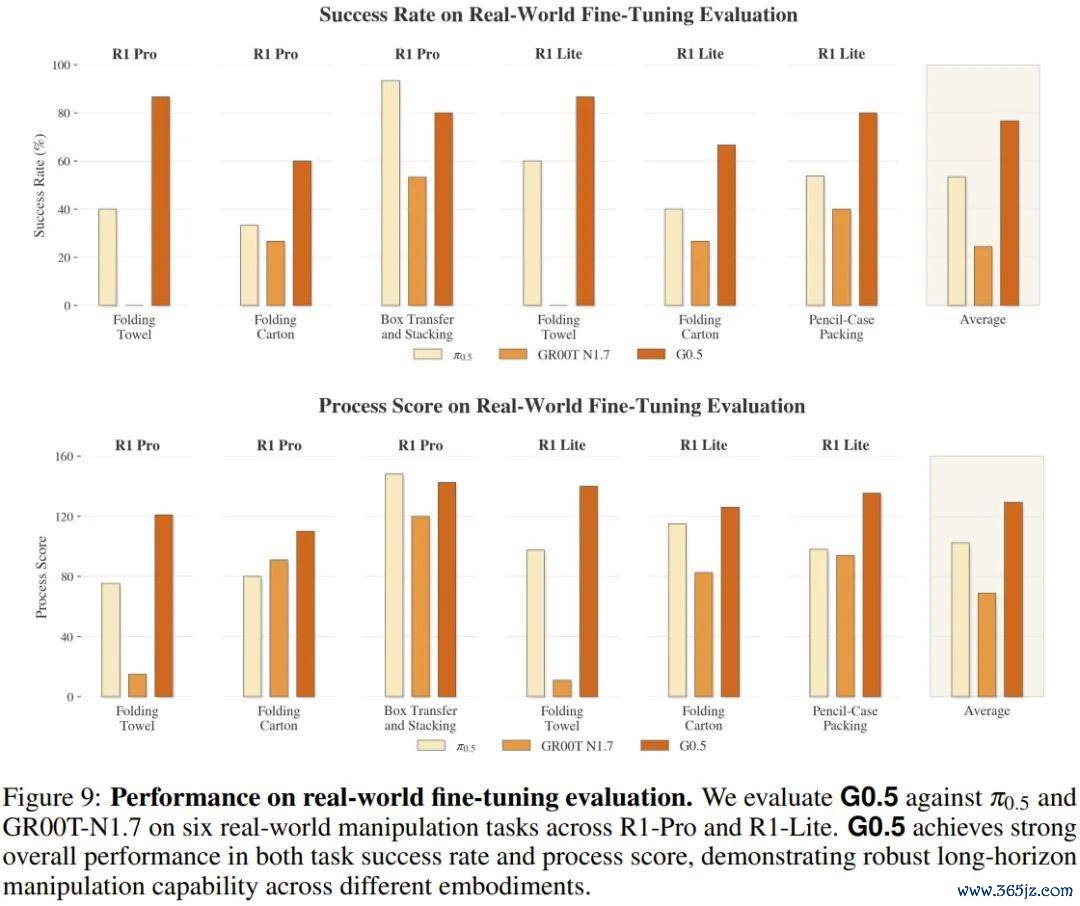
同等条目下,G0.5 的平均胜利率 76.7%,比 π0.5 的 53.0% 跨越 23 个百分点,比 GR00T-N1.7 的 24.4% 跨越一倍过剩。
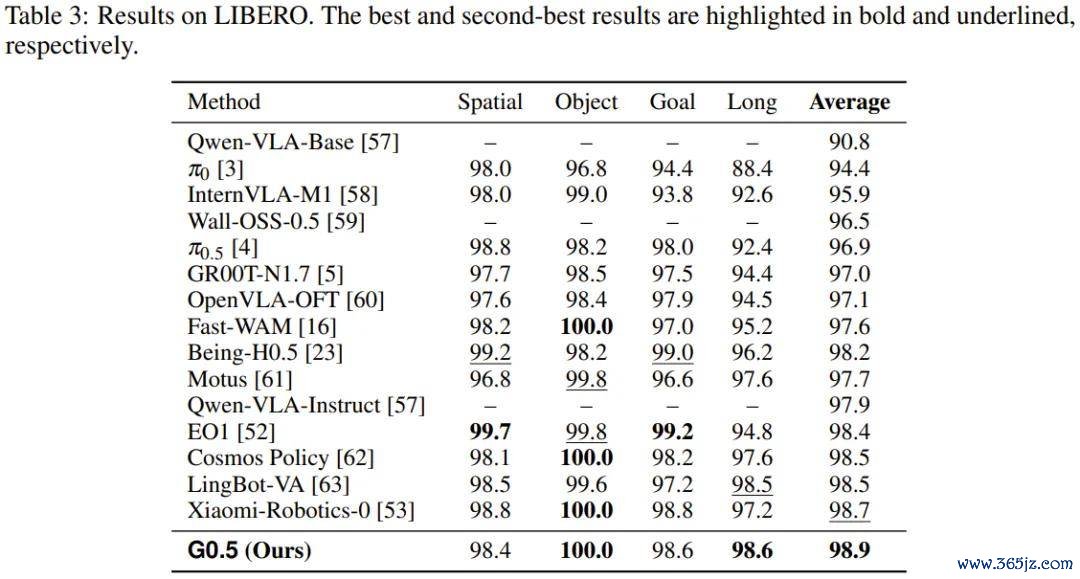
仿真基准(LIBERO / RoboTwin 2.0 / SimplerEnv-Bridge)
三项仿真测试遮掩了单臂指示奴婢(LIBERO)、双臂配合操作(RoboTwin 2.0)和跨数据集迁徙(SimplerEnv-Bridge)三类场景。
G0.5 在 LIBERO 上以 98.9% 的收成位居现时已公开收尾的首位,尤其在 LIBERO-Long(长要领列任务子集)上以 98.6% 的收成超越扫数对比模子。这恰正是对长程推理才能最径直的考验。
傍边滑动检察
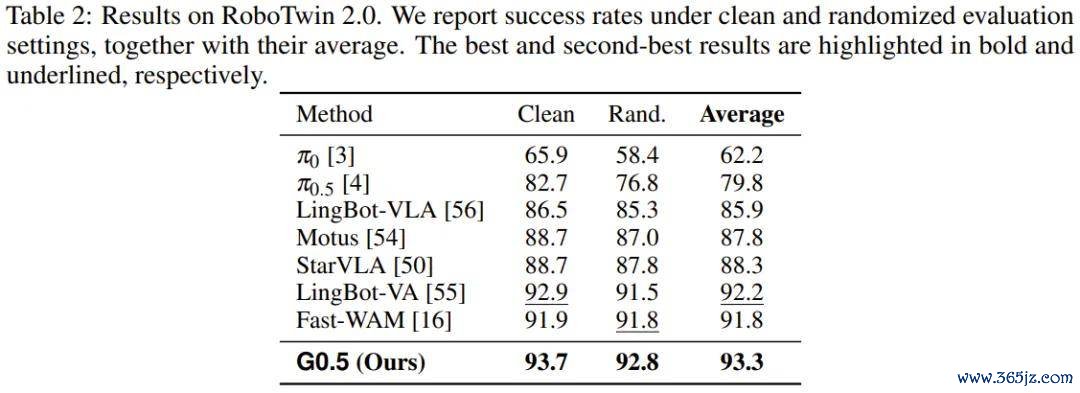
RoboTwin 2.0 包含特等 50 个双臂任务,G0.5 以 93.3% 的均值刷新了该基准的最高记录。
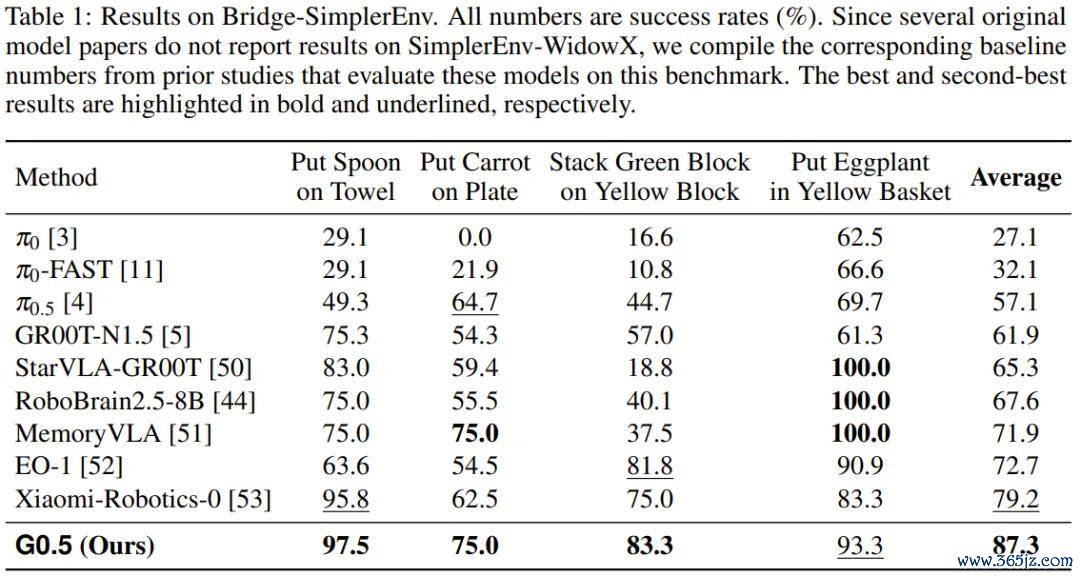
G0.5 在 SimplerEnv-Bridge 上也达到 87.3% 的平均收成,特等其它扫数模子。
长程转移操作(BEHAVIOR-1K)
这是 7 项评测里门槛最高的一项,亦然最能阐发问题的一项。
BEHAVIOR-1K 挑战赛由 50 个无缺家庭场景任务组成,每段演示平均时长 6.6 分钟,最长达 14 分钟,机器东谈主需要适度 R1 Pro 在房间法式的空间里导航、取物、使用电器、整理物品,其中任何一个中间要领的失败王人会影响后续扫数程度。

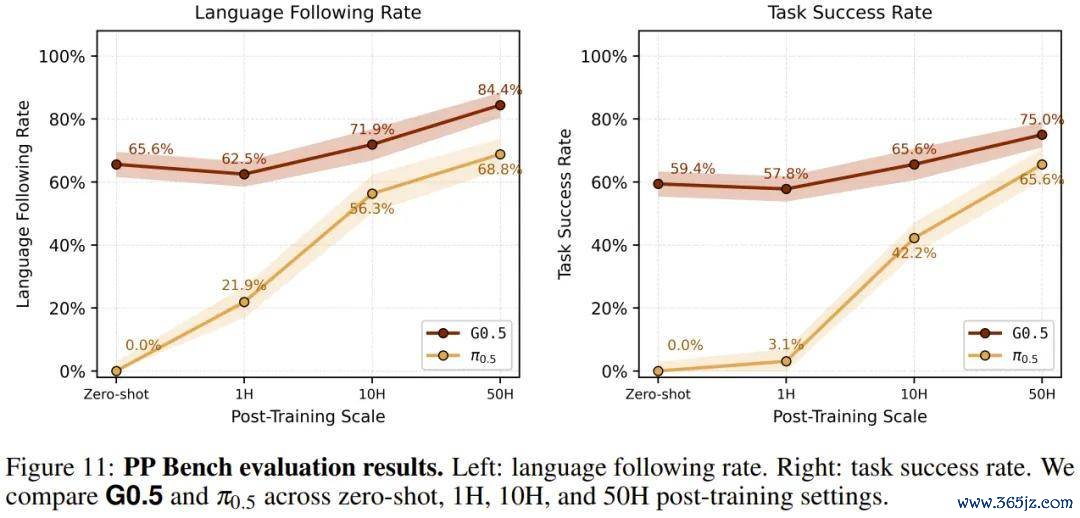
G0.5 使用单个 checkpoint、仅经过 1 个后训导 epoch,Task Success Score 便达到 0.2904,不仅超越了 π0.5 训导 4 个 epoch 的收成(0.2626),也超越了使用 4 个 checkpoint 集成的赛事冠军(0.2605)。训导加多至 4 个 epoch 时,G0.5 的得分普及至 0.3136。在 50 个任务中,G0.5 在 29 个上起首 π0.5,π0.5 只在 15 个上起首 G0.5。
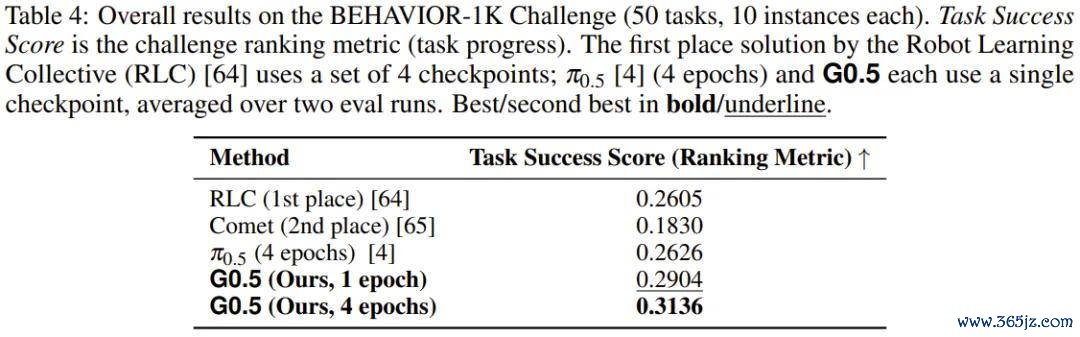
1 个 epoch 赢过 4 个 epoch,单模子赢过集成决议。这组数字径直讲明相反来自预训导底座的质地,而非微调政策。
架构翻新,而非数据堆叠
G0.5 能赢得这些收成,根源在于星海图对现时 VLA 主流架构作念出的一个判断:问题不在于数据量,而在于 VLM 被放错了位置。
往日几年,VLA 领域的主流作念法是「VLM 算作编码器」:让一个预训导好的视觉-讲话模子郑重认知图像和讲话,然后把它的输出算作条目信号,传递给另一个独处训导的「动作大家」(频频是扩散模子或流匹配收罗)来生成最终适度指示。
这种单干有表现的效用上风。但也有代价:VLM 在预训导中积攒的想维链(CoT)、高下体裁习、辅导设备等中枢才能,只可经过这谈压缩瓶颈迤逦影响最终动作,即 VLM 成了一个条目编码器,而非信得过的决策者。
G0.5 的采选是透彻去掉这谈瓶颈,让吞并套模子权重、在吞并条自总结序列里,同期完成推理和动作生成。

图像、讲话、推理陈迹、物理动作,在 G0.5 里一齐被滚动为分享词汇表中的 token,经过吞并个 Transformer 解码器、吞并次前向传播生成。这么一来,推理就成了动作的组成部分。
为了让这套自总结道路在基础模子鸿沟上保持实用,G0.5 引入了三项环节遐想。
跨实质动作编解码器(ActionCodec):将预训导阶段涵盖的 18 种机器东谈主实质数据统一映射到 27 维动作空间,每类通顺部件(左臂、右臂、躯干)对应结构化的动作 token。更焦躁的是,推理时只生成现时需要转移的部件的 token,开云的登录网址静止环节径直跳过。这种寥落展望机制,让自总结 VLA 在高频适度场景下信得过变得可行。
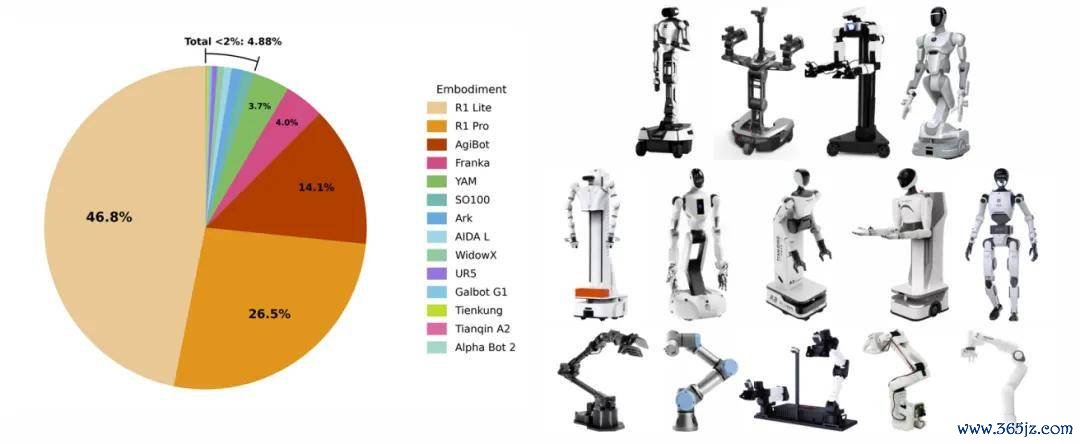
预训导数据中包含的实质。左侧饼图总结了预训导数据聚首不同实质类别的相对比例。
原生想维链(Native CoT):模子在生成动作之前,先在吞并条序列里输出四类推理 token:原子子任务文本、策动对象范围框、二维结尾扩充器轨迹、动作辅导。这些推理 token 与动作 token 受吞并个交叉熵亏空函数看管。实验清醒,在「面包放入空气炸锅」任务上开启原生 CoT 后,胜利率普及了 30 个百分点;在「培根煎制」上普及 35 个百分点 —— 这两个任务王人是模子从未见过的散播外场景。
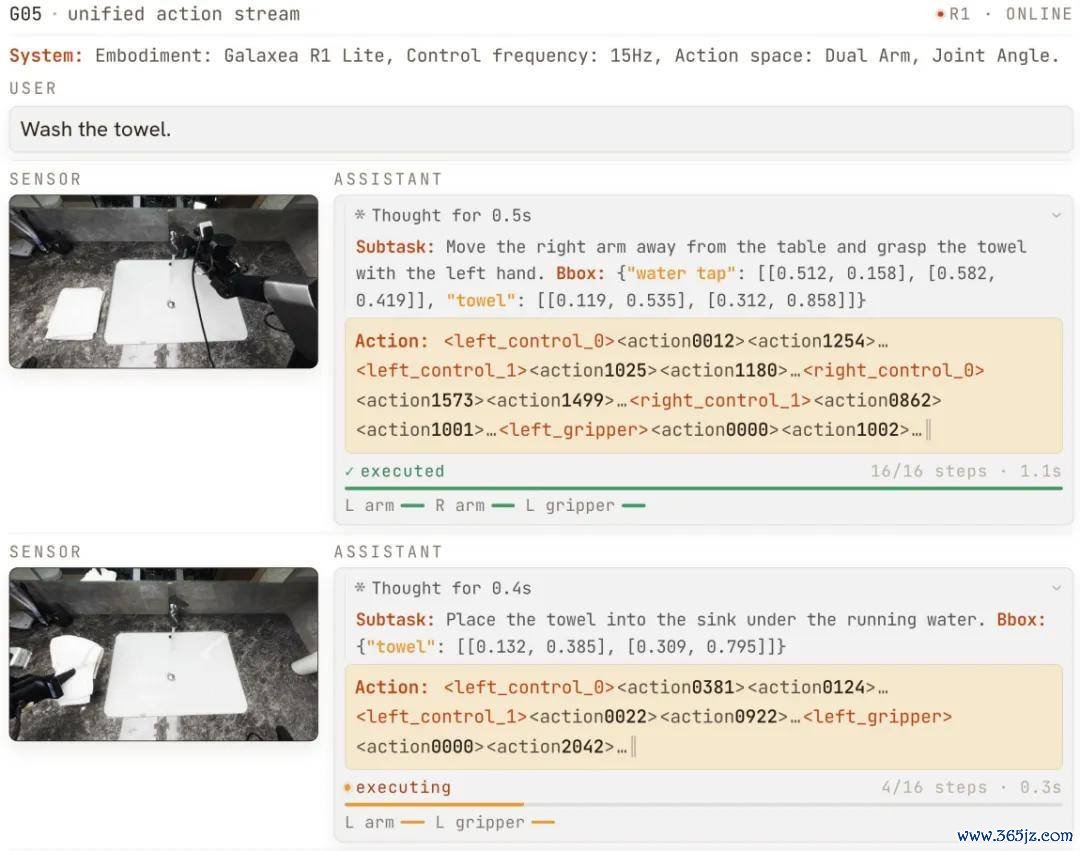
G0.5 在 R1 Lite 上零样本扩充「把毛巾放进洗手池」:在吞并自总结流中,模子先生成想考(子任务、策动物体框),再输转移作 token,并从每一帧不雅测闭环重策动。
视觉操心模块:在 Vision Transformer 的每四层中插入解析的时空谨慎力模块,将多秒历史帧的视觉信息轻量级地融入现时决策。训导时特殊加入 30% 的历史帧偶而丢弃机制,小心过拟合的同期,让模子学会在历史信息缺失机依然得当运行。这一遐想对 BEHAVIOR-1K 里转移箱子到储物间、整理卧室等需要反复穿越空间的长程任务恶果尤为表现。
大义灭亲:用当然讲话径直适度机器东谈主行为
统一自总结架构还带来了另一个才能:通过改写当然讲话辅导,径直编削机器东谈主的动作格调处扩充细节,无需再行训导。这是此前在 VLA 领域基本莫得被系统考证过的新才能!
面前,这套才能在 G0.5 上得到了两个层面的系统性考证。
第一层:想维链对动作的增益随任务长度放大。
星海图团队在单个预训导 checkpoint 上,通过切换推理模式(开启/关闭 CoT)和动作解码状貌(自总结 AR/流匹配 FM),作念了一组严格适度的消融实验。
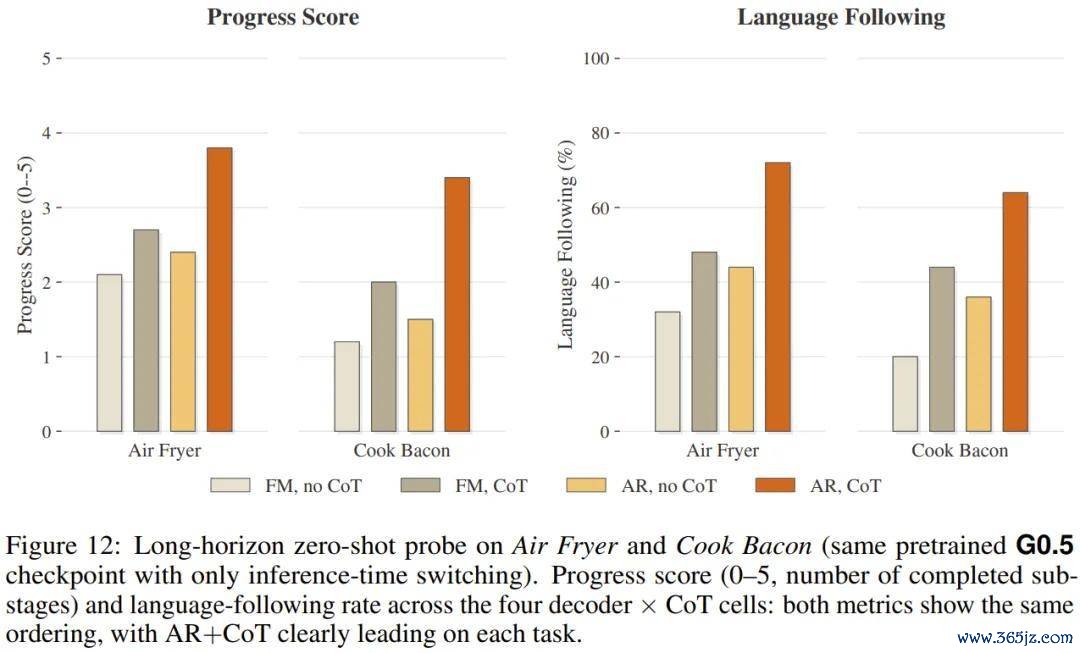
收尾清醒,在单阶段的 Pick-and-Place 任务上,开启 CoT 对自总结模式的胜利率普及只须 3.1 个百分点。但跟着任务阶段加多,这个差距急剧拉大:在五阶段的「面包放入空气炸锅」任务(入场→开门→抓面包→放入→关门)上,开启 CoT 带来 30 个百分点的普及;在相通是五阶段的「培根煎制」任务上,普及达到 35 个百分点。

这阐发想维链的价值不在于匡助模子「想明晰简略的事」,而在于通过逐阶段的子任务解析与策动定位,小心长程任务里的造作积攒和景色漂移。
第二层:辅导改写不错径直调控动作粒度。
在上述散播外任务上,星海图进一步把每个阶段的苟简指示(举例「通达门」)改写为带有丰富副词和空间修饰语的版块(「轻轻地把门弥散通达」)。这种改写并莫得引入任何新的训导数据,仅仅让指示捎带了更细粒度的扩充意图。
收尾:空气炸锅任务的胜利率在 AR+CoT 基础上再普及 15 个百分点,培根任务再普及 10 个百分点,两项从未出面前预训导数据中的复杂任务无缺胜利率均破裂 50%。
为什么这件事只须自总结架构能作念到?
对比数据给出了回复。相通开启 CoT、相通分享预训导权重,仅把动作解码从自总结切换为流匹配(FM)模式:CoT 对 FM 在空气炸锅任务上的普及只须 10 个百分点,培根任务上相通是 10 个百分点;均不及 AR 模式下普及幅度的三分之一。
星海图团队对 CoT 输出的准确率进行了东谈主工评分,AR 和 FM 模式下的推理质地临近(PP Bench 约 90%,空气炸锅约 85%,培根约 80%)。因此这个差距不来自推理自己的质地,而来自动作的解码状貌:自总结 token 与推理 token 共处吞并条序列,动作生成时不错径直回看 CoT 内容;而流匹配大家在产活泼作前,仍是把推理轨迹压缩进了一个紧凑的条目向量,细节丢失了。
这亦然 G0.5 的中枢主义得到实验维持的最径直字据:推理和动作必须分享吞并个高下文,才能让「想考」信得过驱动「行为」。
大义灭亲
G0.5 的 PP Bench 收尾还揭示了另一个值得关爱的维度:视觉高下文对讲话奴婢的影响。
在 50 小时后训导建立下,法式指示(仅有笔墨称号)的讲话奴婢率为 84.4%,任务胜利率为 75.0%。星海图团队进一步向模子输入了策动物体和容器的剪辑视觉图像算作特殊高下文,讲话奴婢率偶而跃升至 98.4%,任务胜利率升至 84.4%。
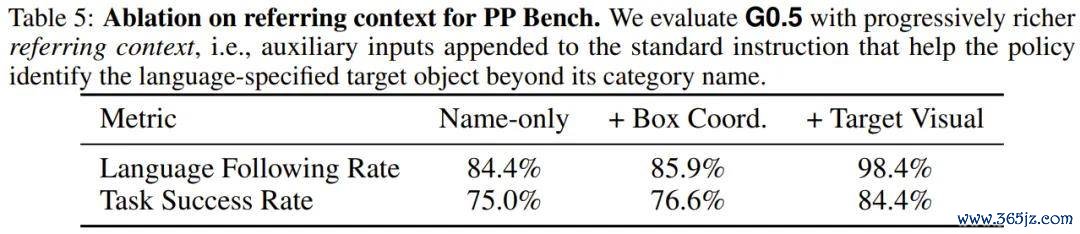
这阐发关于语义歧义的长尾物体(举例用华文标注「马」字的中国象棋棋子),视觉高下文提供的细粒度外不雅思绪好像弥补纯讲话样式的不及,而 G0.5 的多图像接口不错当然地给与并欺诈这类补充信息。
操控机器东谈主行为的状貌正在向操控大讲话模子的状貌看管。用户无需再行集合数据或发起新一轮微调,仅靠当然讲话的措辞采选,就能革新机器东谈主在生分场景下的行为粒度与扩充格调,真像是「大义灭亲」。
全栈闭环下的中国翻新
G0.5 是星海图「整机+智能」全栈道路的居品。这家训诫于 2023 年 9 月、累计融资近 50 亿东谈主民币的公司,自研的 R1 Pro 和 R1 Lite 轮式双臂机器东谈主平台已处事包括斯坦福、Physical Intelligence、华为在内的公共近百家顶尖具身智能机构,并被用于 π0.5 真机数据的集合。
G0.5 基于 Qwen3.5 2B 视觉-讲话模子运行化,预训导数据涵盖 18 种机器东谈主实质,与约 1 亿条视觉-讲话问答数据合资训导(其中含 5000 万条具身场景 VQA),通盘预训导过程约 12 万步。
这种全栈闭环的道理在于:星海图的实质数据助力了 G0.5 的预训导,G0.5 的泛化才能又反过来裁减了实质适配的老本。自总结架构则不错让这个闭环里积攒的推理才能传导到机器东谈主的物理行为里。
值得一提的是,架构道路上的判断已不啻 G0.5 一例。星海图团队前段时辰发布的 Fast-WAM 论文(arXiv:2603.16666),活着界动作模子(WAM)标的给出了相通的底层判断:明确的改日想象对动作性能的孝顺远小于预训导阶段的视频合资建摹自己,即信得过焦躁的是训导时学到的寰宇表征,而不是推理时造出的展望帧。
两篇责任指向的是吞并个标的:在具身智能的底层建模上,中国团队正在作念原创性的架构判断,而不仅仅在既有框架上堆参数、堆数据。
诚然开云的世界杯中国登录网址,具身智能还有很长的路要走,但架构的采选仍是在决定谁走得更快。
 备案号:
备案号: